スタディとソルバー
COMSOL Multiphysics® バージョン 5.2a では, 新しいソルバーが加わり, また既存ソルバーが更新され, 時間領域の波動伝播に吸収層を利用できるようになり, さらにスタディのマルチフィジックス連成を有効または無効にする新しいマルチフィジックス表など, 機能が強化されています. スタディとソルバーに関する COMSOL Multiphysics® バージョン 5.2a のアップデートは, 以下のとおりです.
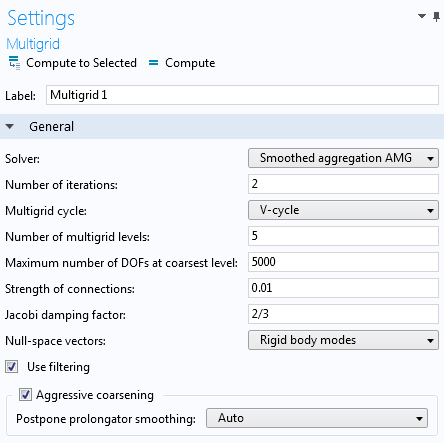
新しい平滑化集合代数的マルチグリッド (AMG) ソルバー
最先端の代数的マルチグリッド (AMG) ソルバーである 平滑化集合AMG ソルバーは, 広範囲の用途に活用することができます. この新しいソルバーは, 従来から利用可能な AMG ソルバーと比較して, 構造解析のための線形弾性など, 場変数が強力に連成された問題により適しています. 幾何学的マルチグリッド (GMG) 法と比較した AMG 法の主な利点として, 粗いレベルのグリッドにメッシュを作成する必要がありません. このことは, 粗いメッシュの作成が困難または不可能なことがある大規模な CAD モデルの場合に有益です.
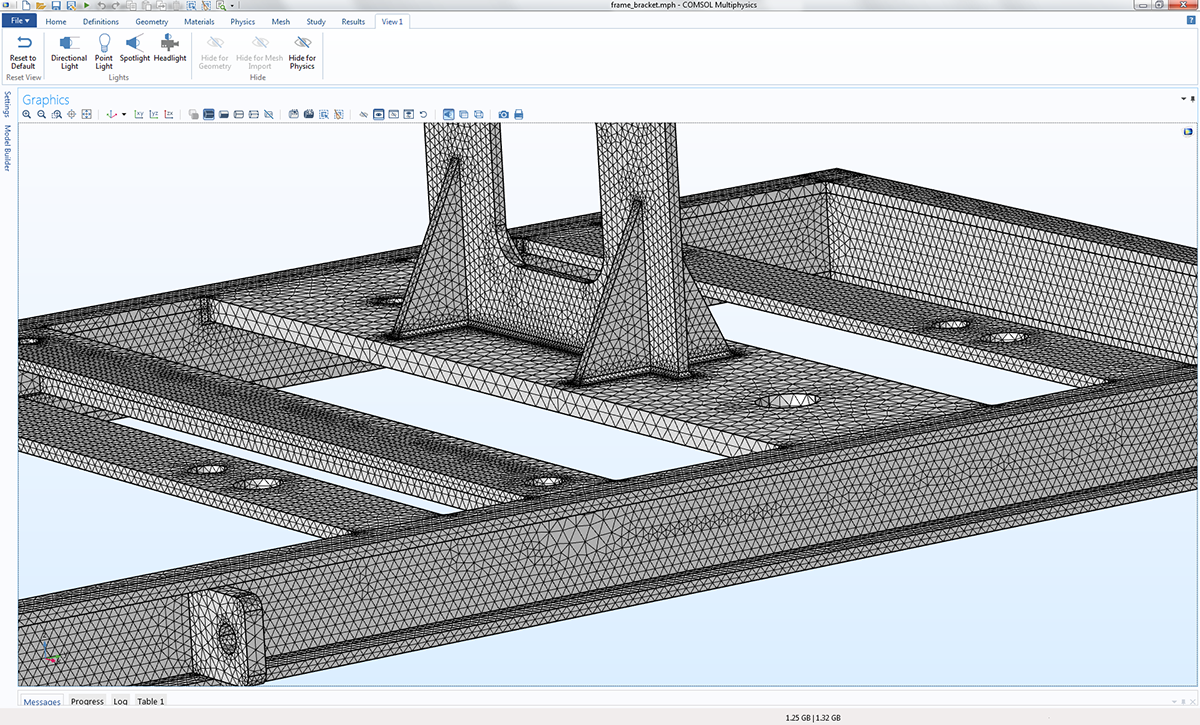
ブラケットのあるフレームの構造解析のためのメッシュ. 図示されているように, このモデルに粗いメッシュを作成することは不可能です. このモデルは, 250,000 の四面体二次要素と 1282kの自由度を持ちます. 求解プロセスは, 前提条件子として新しい 平滑化集合AMG を用いて, 共役勾配ソルバーで 51 回反復させる必要があります. 求解時間は 65 秒, メモリ要件は Intel® Xeon® プロセッサー E5-1650 3.5 GHz 搭載のワークステーションで 3.5 GB です.
ブラケットのあるフレームの構造解析のためのメッシュ. 図示されているように, このモデルに粗いメッシュを作成することは不可能です. このモデルは, 250,000 の四面体二次要素と 1282kの自由度を持ちます. 求解プロセスは, 前提条件子として新しい 平滑化集合AMG を用いて, 共役勾配ソルバーで 51 回反復させる必要があります. 求解時間は 65 秒, メモリ要件は Intel® Xeon® プロセッサー E5-1650 3.5 GHz 搭載のワークステーションで 3.5 GB です.
平滑化集合 AMG 法は, 自由度 (DOF) ノードを接続基準に基づき節点集合に分割することで機能します. 各節点集合は次のレベルのマルチグリッドで新しいノードになり, 一定の数のレベルに到達するか, または DOF の数が十分に小さくなるまで, アルゴリズムによって処理が進められます.
Introduction to COMSOL Multiphysics マニュアルでは, 新しい 平滑化集合 AMG ソルバーを使用したメッシュ収束の解析方法が手順を追って詳しく説明されています.
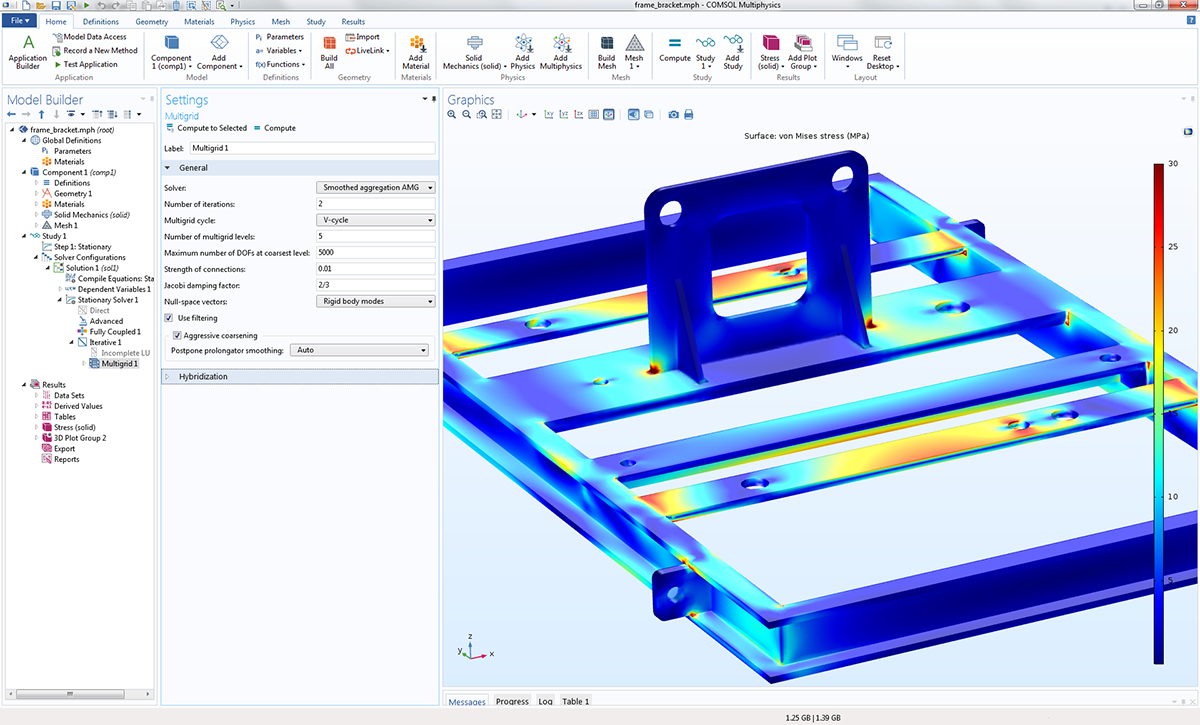
ブラケットがあるフレームの構造解析から計算された応力と, 平滑化集合 AMG ソルバーの設定ウィンドウ.
ブラケットがあるフレームの構造解析から計算された応力と, 平滑化集合 AMG ソルバーの設定ウィンドウ.

ハードテールアルミニウムマウンテンバイクのフレームの構造解析. このモデルは, 194,000 の四面体二次要素と 1,157,000の 自由度を持ちます. 求解プロセスは, 前提条件子として新しい 平滑化集合AMG を用いて, 共役勾配ソルバーで 117 回反復させる必要があります. 求解時間は 96 秒, メモリ要件は Intel® Xeon® プロセッサ E5-1650 3.5 GHz 搭載のワークステーションで 3.1 GB です.
ハードテールアルミニウムマウンテンバイクのフレームの構造解析. このモデルは, 194,000 の四面体二次要素と 1,157,000の 自由度を持ちます. 求解プロセスは, 前提条件子として新しい 平滑化集合AMG を用いて, 共役勾配ソルバーで 117 回反復させる必要があります. 求解時間は 96 秒, メモリ要件は Intel® Xeon® プロセッサ E5-1650 3.5 GHz 搭載のワークステーションで 3.1 GB です.
アプリケーションライブラリパス:
Structural_Mechanics_Module/Applications/bike_frame_analyzer_llsw
{kind=link}
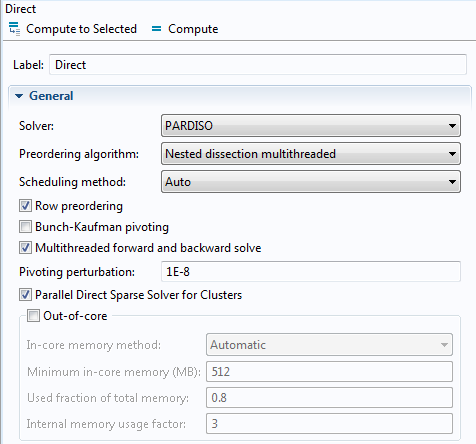
クラスター向けの新しい直接法ソルバー
クラスター向けの新しい直接法ソルバーとして, Intel® Math Kernel Library ソフトウェア製品の Parallel Direct Sparse Solver for Clusters (クラスター向けの並列直接法疎行列ソルバー) が追加されました. クラスター上でモデルを実行する場合に PARDISO オプションを選択すると, このソルバーが自動的に選択されます. 共有メモリ計算で使用される PARDISO ソルバーも, Intel® Math Kernel Library ソフトウェア製品で利用可能です. 以前のバージョンでは, クラスター上でモデルを実行する時に PARDISO ソルバーオプションを選択すると, 代わりに使用できるクラスター上の直接法ソルバーがないため, MUMPS ソルバーが使用されました. Parallel Direct Sparse Solver for Clusters チェックボックスを未選択にすると, 従来の方法に戻せます.
{kind=link}
MUMPS ソルバーのアップグレード
直接法 MUMPS ソルバーがアップグレードされ, 新しく実装された OpenMP® API 並列性により, パフォーマンスが大幅に向上しました.
領域分割ソルバーの最適化
特に強力に連成されたマルチフィジックス現象など, 大きな問題を処理する場合, 以前は直接法ソルバーが唯一のオプションでしたが, このような問題を処理できるよう領域分割ソルバーの精度を向上して最適化しました.
- デフォルトにより, ソルバーの領域分割には METIS アルゴリズムが使用されます.
- 最適化されたセットアップ段階を追加してソルバー機能を強化し, クラスター上での実行時の通信の効率化を図りました.
- 代数的マルチグリッド (AMG) 法を用いて, このソルバーの粗いグリッドを設定できるようになりました. 非常に粗いグリッドを使用でき, またこの技法ではメッシュを作成する必要がないので (複雑な CAD モデルには, 粗いメッシュ作成は失敗する可能性があります), この設定が望ましいと言えます.
最適化された領域分割ソルバーの使用例を示すアプリケーションライブラリへのパス:
Acoustics_Module/Tutorials/transfer_impedance_perforate
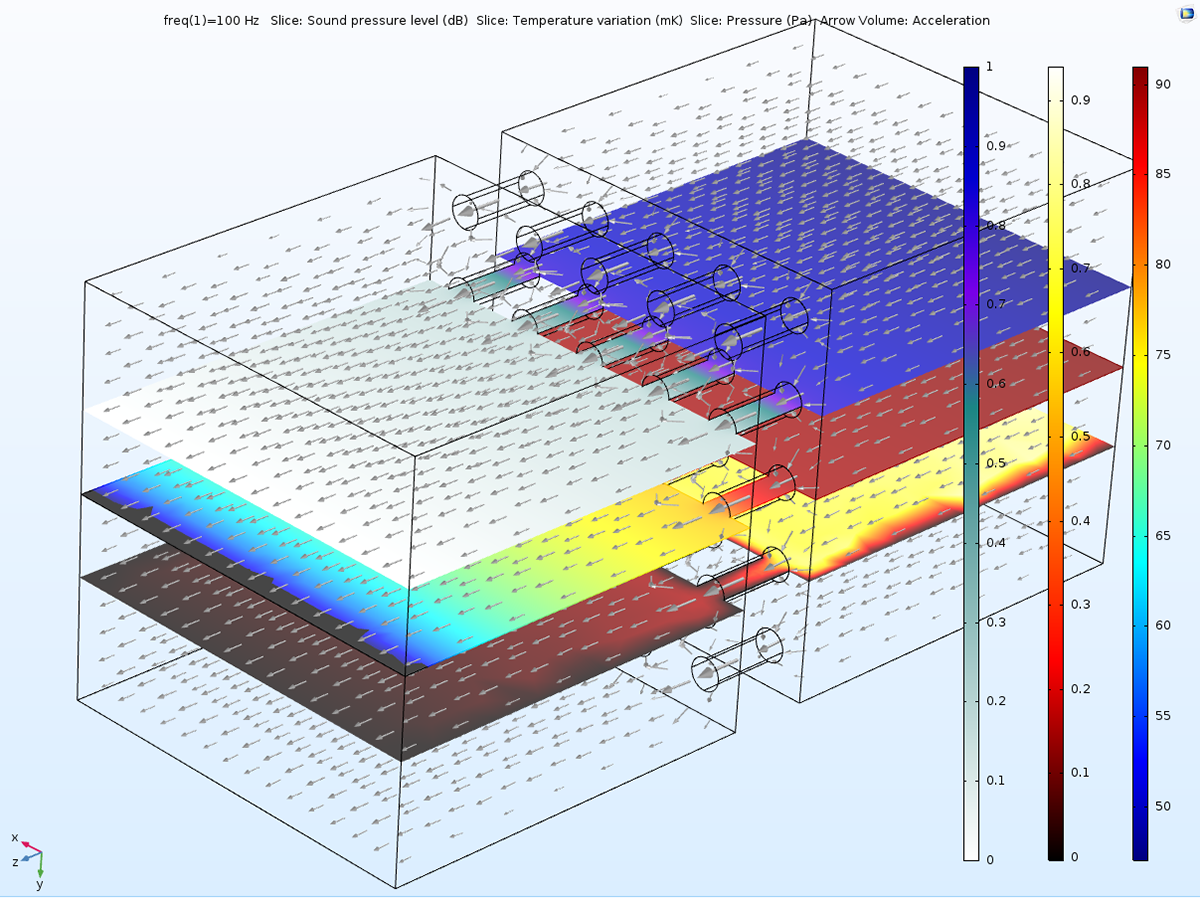 多孔板モデルの伝達インピーダンスの速度と全音圧.
このモデルは, 領域分割法で前提条件を課し, GMRES 法により 18 回反復させて求解されています.
この領域分割法では, 10 個のドメイングループを使い, 計算処理を 30 のサブドメインに自動的に分割しています.
サブドメインは, この強力に連成された問題に対する唯一の実現可能なソルバーである直接法ソルバーによって求解されます.
計算処理では, サブドメインの求解ステップ間で LU ファクターの再計算とクリアを行い, 14.3 GB の RAM が必要となります.
計算処理には 1 時間 21 分かかります.
自由度の合計数は2,579,000で, 409,000 の四面体要素が使用されています.
比較として, 直接法ソルバーを使用した場合の必要メモリ量は120 GB です.
多孔板モデルの伝達インピーダンスの速度と全音圧.
このモデルは, 領域分割法で前提条件を課し, GMRES 法により 18 回反復させて求解されています.
この領域分割法では, 10 個のドメイングループを使い, 計算処理を 30 のサブドメインに自動的に分割しています.
サブドメインは, この強力に連成された問題に対する唯一の実現可能なソルバーである直接法ソルバーによって求解されます.
計算処理では, サブドメインの求解ステップ間で LU ファクターの再計算とクリアを行い, 14.3 GB の RAM が必要となります.
計算処理には 1 時間 21 分かかります.
自由度の合計数は2,579,000で, 409,000 の四面体要素が使用されています.
比較として, 直接法ソルバーを使用した場合の必要メモリ量は120 GB です.
時間依存波動シミュレーションのための無反射吸収層
節点による不連続ガラーキン法を使い, 時間領域における波動伝播の吸収層について, 組み込みサポートが導入されました. 吸収層は, 無反射境界条件として用いて, 計算ドメインの外側に吸収層特性を持つサブドメインを追加することで作成します. これらの吸収層を座標変換によって拡張し, フィルターを使用することで波動を減衰させます. 吸収層の外側の境界には, 局所的低反射境界条件を用います. こうすることで, 吸収層からの反射が効果的に低減され, 散乱の問題や, 無反射境界条件を必要とするその他の問題のための計算ドメインを減らす方法として多目的に利用できます.
新しい不連続ガラーキン法の使用例を示すアプリケーションライブラリへのパス:
Acoustics_Module/Ultrasound/ultrasound_flow_meter_generic Acoustics_Module/Tutorials/gaussian_pulse_absorbing_layers
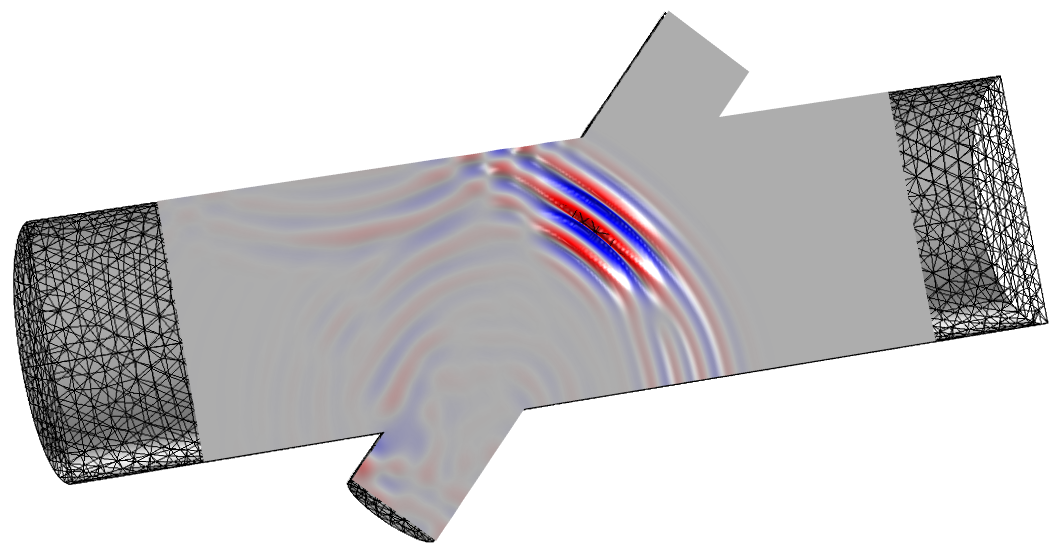 モデルの対称面のガウス圧パルス. 新たに導入された不連続ガラーキン法により, メインフローチャネルの左右で吸収層に波動が吸収されます.
モデルの対称面のガウス圧パルス. 新たに導入された不連続ガラーキン法により, メインフローチャネルの左右で吸収層に波動が吸収されます.
パラメーターリストを使用するバッチモードのパラメトリックスイープ
パラメーター値のリストを入力として使い, ユーザーインターフェースでパラメーターを定義せずに, スイープを実行できるようになりました. 以前は, この機能を利用するには, COMSOL Desktop® でパラメトリックスイープによってスイープを構成する必要がありました. パラメーター値ごとにスイープが実行され, 結果が別ファイルに保存されます. リストは, ファイルから読み取ることもできます.
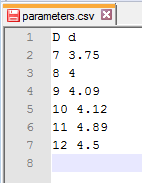
入力引数として使用する2つのパラメーターのリストを指定したバッチコマンド例:
comsolbatch.exe -inputfile feeder_clamp.mph -pname D,d -plist 7,3.75,8,4,9,4.09,10,4.12,11,4.89,12,4.5
パラメーターリストの指定にファイル parameters.csv を用いている同じスイープの例:
comsolbatch.exe -inputfile feeder_clamp.mph -paramfile parameters.csv
{kind=link}
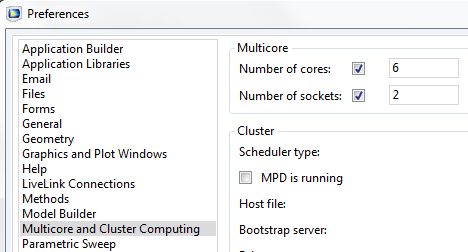
ソケット数の指定
コアの数を指定するための設定に加え, COMSOL Multiphysics® では, マルチソケットコンピューターで使用するソケットの数を指定する新しいオプションを利用できるようになりました. この設定は, Preferences (プリファレンス) ウィンドウの Multicore and Cluster Computing (マルチコアとクラスター計算) セクションで利用することができます.
{kind=link}
スタディでマルチフィジックス連成を有効/無効にする新しい選択項目
従来から利用可能な求解のためのフィジックスインターフェース表に加え, 新しいマルチフィジックス表を使い, 利用可能なマルチフィジックス連成を選択的に有効または無効にすることができます. これにより, マルチフィジックス連成の事前構成済みオプションを従来と同じように使いながら, モデルに複雑性を逐次追加する作業が容易になります.
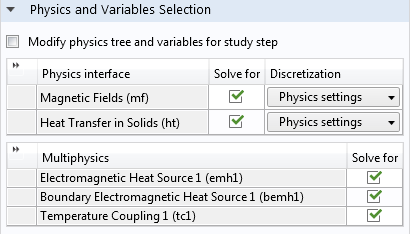{kind=link}
スタディから無限要素と完全整合層を有効/無効化
モデルツリーの Definitions (定義) ノードを使い, スタディから Infinite Element Domain (無限要素ドメイン) ノードと Perfectly Matched Layer (完全整合層) ノードを有効または無効にできるようになりました. スタディで Modify physics tree and variables (フィジックスツリーと変数の変更) オプションを有効にすると, この機能を使用できます.
{kind=link}
OpenMP および OpenMP のロゴは, アメリカおよびその他の国における OpenMP Architecture Review Board の登録商標です.