
よく寄せられる質問のひとつに, COMSOL Multiphysics® ソフトウェアで解けるモデルの大きさはどのくらいですか, というものがあります. これはある意味, 非常に簡単な質問ですが, 数値計算法, モデリング手法, 求解アルゴリズム, コンピューターのハードウェア性能, および計算量の多い問題への最適なアプローチ方法について解説していくと, 長い話になります. では, このトピックをより深く掘り下げてみましょう.
編集者注: 本ブログは最初2014年10月24日に公開されたものです. その後, 新機能を反映させるために更新されました.
データを見ていきましょう
まず, あるドメイン内の定常温度分布の 3D モデルを設定し, 自由度 (DOF) の増加に伴う必要メモリ量と解答時間を調べていきます. つまり, このモデルは, 一般的なデスクトップワークステーションマシン— この場合は32 GB RAM とソリッドステートドライブ (SSD) 付きの Intel® Xeon® W-2145 CPU — のデフォルトソルバーを使用して, 徐々に細かいメッシュで解かれます.
まず, モデルサイズが大きくなったときに必要なメモリを, 仮想メモリと物理メモリという2つの報告量から見ていきます. 仮想メモリは, ソフトウェアがオペレーティングシステム (OS) に要求しているメモリ量です. (これらのデータは Windows® マシンのものですが, サポートされているすべての OS のメモリ管理は非常によく似ています.) 物理メモリは, 占有されている RAM メモリの量です. OS やコンピューター上で実行されている他のプログラムも RAM の一部を占有する必要があるため, 物理メモリは常に仮想メモリと搭載されている RAM の量の両方を下回ることになります. ある時点で, 物理 RAM の空き容量が使い果たされ, データの大部分が SSD に存在することになります. また, ある時点で, モデルがそれ以上大きくなると, メモリが足りなくなり, モデルを解くことができなくなります. コンピューターにメモリを追加すれば, より大きなモデルを解くことができるのは明らかです. また, 直線外挿することで必要なメモリ量を予測することができます.
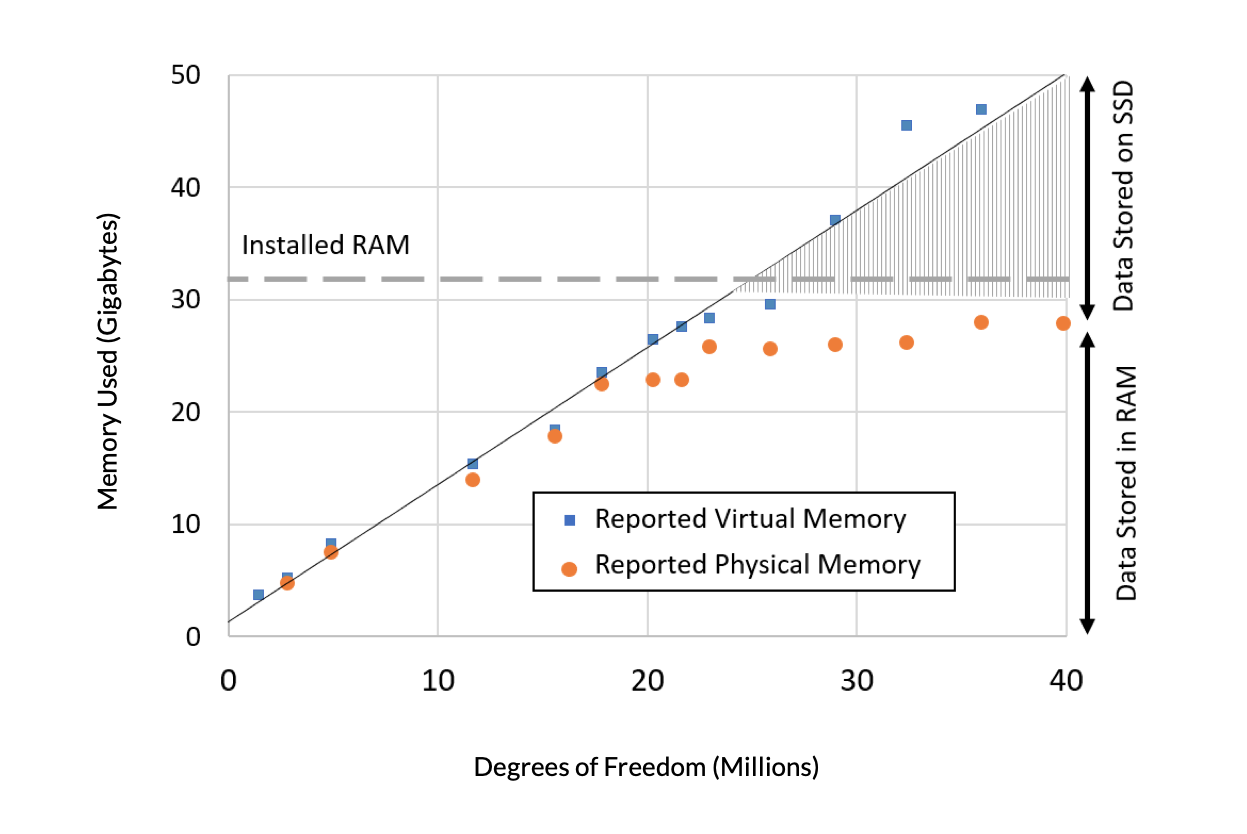
図1. 固体内の熱伝導を含むモデルの問題サイズ (数百万自由度) に対する報告された仮想メモリ (青) と物理メモリ (オレンジ) の必要量. 32 GBの RAM を搭載したコンピューターが使用されました.
次に, この問題の求解時間と, 再び, 自由度との関係を見てみましょう. 求解時間には2つの領域があります. 必要な仮想メモリが搭載 RAM より少ない領域では, 2次の多項式があてはまり, この曲線はほぼ直線になります. 残りのデータでは, 仮想メモリが搭載 RAM より多い領域で, 別の2次の多項式があてはまります. この領域では, 仮想メモリに保存されたモデルデータにアクセスするのに時間がかかるため, 勾配がより急になります.
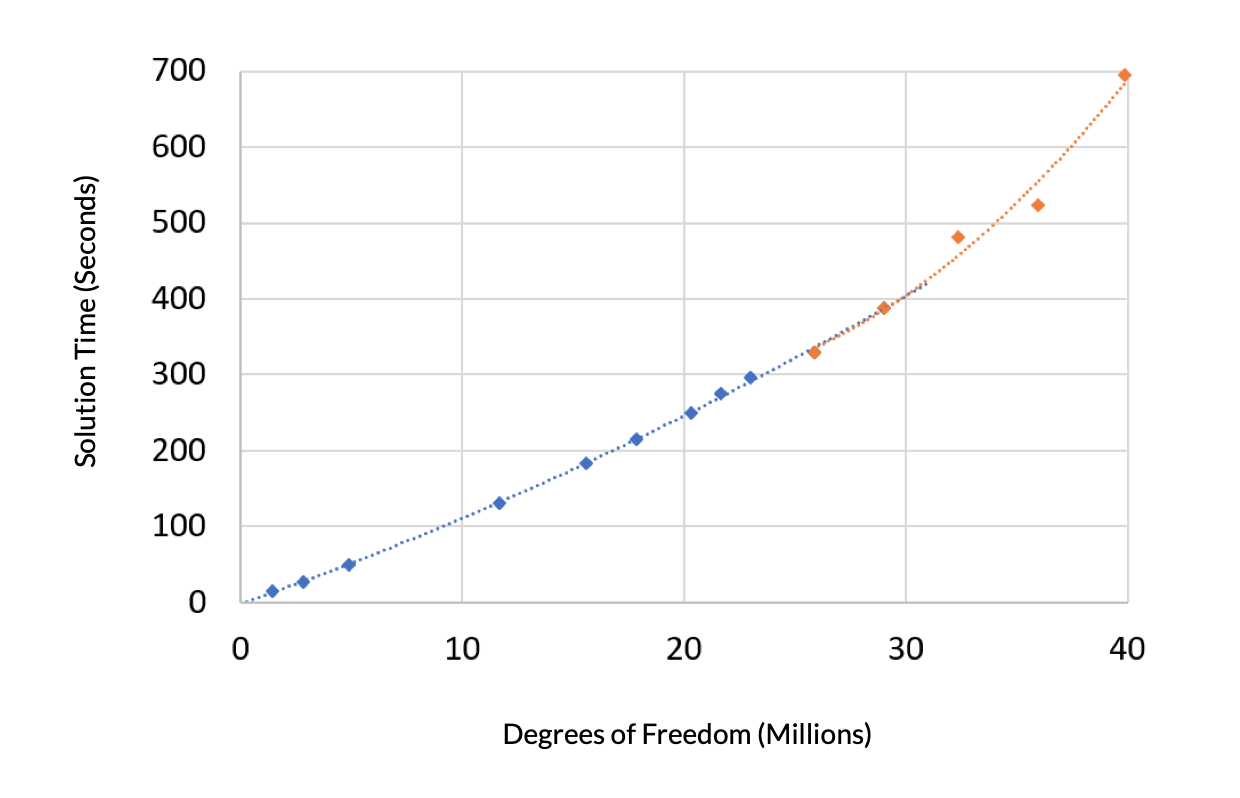
図2. 問題サイズが利用可能な RAM より大きい場合, 求解時間対自由度の傾きが大きくなります.
必要なメモリは常に同じか?
必要なメモリ容量に関する先行データが常に正しいかどうか問うことができます. おそらくお察しの通り, 答えはノーです. 非常に類似した問題以外では, 先行データに予測的な価値はほとんどありません.
モデルに加えられる典型的な6つの変更
これらの曲線を上下に変化させるために, 現在のモデルに加えることができる一般的な変更にはどのようなものがありますか? 以下に, いくつかの異なる例を取り上げます.
1. 時間領域での求解
時間依存型ソルバーを使って時間領域の問題を解くと, 定常状態の問題を解く場合と比較して, より多くのデータをメモリに保存する必要があります. アルゴリズムの概要については, “時間依存問題における自動時間ステップと次数選択” をご覧ください.
2. 線形ソルバーの種類の切り替え
前述の問題は, 反復ソルバーまたは直接ソルバー のどちらかで求解することができます. 反復ソルバーは, 特に問題サイズが大きくなるにつれて, 直接ソルバーよりも大幅に少ないメモリを使用することになります. 直接ソルバーは, 例えば材料特性の差異が大きいためにシステム行列がほぼ悪条件に近いものの超線形にスケールする場合など, 特定の問題にのみ使われます.
3. 非線形性の導入
単一のフィジックスの中でも, 材料特性を温度の関数にするなど, 何らかの 非線形性 を導入すると, システム行列が非対称になることがあります. これにより, 必要なメモリ容量が増加します. これを防ぐには, nojac() 演算子を用いて シンボリック微分 を避けることが可能ですが, これは 非線形収束率に悪影響を与える可能性があるので, すべてのケースで行うべきではありません.
4. 要素種類の変更
3D 問題のデフォルトの要素種類は四面体要素ですが, 三角柱や六面体など他の要素種類を使用することもできます. これらの要素は, 要素あたりの接続性が高く, メモリ使用量が増加します. 一方, 要素種類の切り替えは, 特にジオメトリ分割や スウェプトメッシュ と組み合わせた場合, 同じジオメトリに対してより粗いメッシュを作成できるため, 特定のジオメトリ や問題において魅力的です.
5. 要素次数の変更
“固体の熱伝導”を解く際の デフォルトの要素次数 は, 2次ラグランジュです. 線形に変更 すると, メッシュが同じであればモデルの自由度が減少し, また各要素の連結数が減ります. つまり, 各要素内の各ノードが連結する隣接ノードの数が少なくなります. これは, 同じ自由度でもメモリ使用量の減少につながります. 一方, 要素の次数を上げると連結数が大きくなり, 同じ自由度でのメモリ使用量が増えます. さらに, ラグランジュ要素とセレンディピティ要素を切り替えることもでき, 後者の方が要素あたりのノード数が少なくなります. ただし, 要素の次数や種類を変えると, 精度やジオメトリメッシュの必要量に影響が出ることを理解する必要があります. さらに, それ自体が複雑なトピック なので, 要素の次数をデフォルトから変えるのは慎重に行う必要があります.
6. 非ローカルカップリングやグローバル方程式の導入
非ローカルカップリングは, 非隣接要素間の情報を渡すあらゆる種類の追加のカップリング項を含み, しばしばグローバル方程式と組み合わせて使用されます. これらを使用すると, システム行列内の情報量に影響を与え, 多くの場合, 問題が非線形になります. 電流を含む問題で利用できる“端子”境界条件など, 非ローカルカップリングやグローバル方程式を背後に導入する境界条件もあります. 非ローカルカップリングは, ブログ “ “空洞の体積の計算と制御” ” でご説明したように, 手動で実装することも可能です.
異なるフィジックスの求解
では, 異なるフィジックスを求解する場合はどうでしょうか? 前述の例は, 熱伝導のモデリングに関するもので, 有限要素法 (FEM) を用いて (スカラー) 温度場を解くものでした. もし, FEM を使って異なるフィジックスを解くのであれば, 代わりにベクトル場を解くことになるかもしれません. 例えば, 次のような場合です.
- 固体力学
- 流体流れ
- 電磁気学
- 化学種輸送
- 反応流 のような化学工学の問題を解く場合, 自由度の数は, モデルに含める化学種の数に比例します.
これらのフィジックス, あるいは FEM で解かれた他のフィジックスのそれぞれについて, 先に述べたすべての点の影響を再度考慮しなければならないことにご注意ください. また, FEM 以外に目を向けるとどうでしょうか? COMSOL® では, 以下のようなインターフェースや方法が使用可能です. 例えば, 粒子位置の常微分方程式系 (ODE) を解き, FEM と比較して自由度に対するメモリ必要量が非常に低い“粒子追跡” インターフェース. 同じく一連の ODE を求解し, 粒子追跡と同様のメモリ必要量である “光線光学” インターフェース. 電磁波, 音響, および 弾性波 を解くためにFEM に比べて非常に少ないメモリしか使用しない不連続ガラーキン (dG) アプローチ. 最後に, 離散化法のひとつでありながら, 体積ではなく境界を扱う方法の境界要素法 (BEM). これにより, FEM と比較して各自由度に必要なメモリ量が非常に多くなりますが, 同じ精度を得るために必要な自由度は少なくなります. BEM は 音響, 静電場, 電流分布, 静磁気, 波動電磁気学 で実装されています.
最後に, これらの様々な異なるフィジックスをモデルに含めることができるだけでなく, それらを組み合わせて真の マルチフィジックス モデルを構築することができます. その際, このようなモデルは, 完全連成または分離解法のアプローチ, および直接または反復ソルバーのいずれかを使用して解くことができるため, 考えられる 求解アプローチ も考慮する必要があり, これらはすべてメモリ必要量に影響を及ぼします. 以下の表は, いくつかの典型的なフィジックスインターフェースについて, これらの分野の典型的な問題に対するメモリ必要量の概算を示したものです.
| フィジックス | 1ギガバイトあたりの自由度 |
|---|---|
| 伝熱 (固体) | 800,000 |
| 固体力学 | 250,000 |
| 電磁波 | 180,000 |
| 層流 | 160,000 |
この時点で, メモリ必要量を予測することの複雑さについて, ある程度ご理解いただけたと思います. しかし, 実用的な観点から, このような情報は何の役に立つのでしょうか? 日々の作業の観点からすると, 答えは一つに集約されます. それは, “スケーリングスタディを実行する必要がある” ということです. これには, フィジックス, 境界条件, カップリングを全て含む, 目的の離散化を使用した小さなモデルから始めます. まず, このモデルを解き, 必要なメモリを確認しながら, 徐々に自由度を増やしていきます. このデータは通常線形ですが, 直接ソルバーで BEM を使用する場合や, ある種の非ローカルカップリングがある場合など, 自由度の数の2乗に比例して増加することがあります. この情報が得られたら, モデル性能の向上に取り組む準備が整いました.
異なるコンピューターハードウェアによる性能向上
ここで, 先ほどの求解時間と自由度のグラフに戻り, 求解時間を変化させることができる10種類のハードウェアの変更についてご説明しましょう.
ハードディスクドライブの代わりに SSD を使用
これは, 使用される仮想メモリが物理 RAM よりも大幅に大きい領域で重要となります. 先に示した曲線の生成に使用したコンピューターには, ほとんどの新しいコンピューターに共通する SSD が搭載されています. ソリッドステートメモリではなく, 回転するプラッターと移動する読み取りまたは書き込みヘッドを備えたハードディスクドライブ (HDD) では, 求解時間が比較的遅くなります. RAM よりも少ないメモリしか必要としないモデルを解く場合, こちらを選択しても実際の影響はかなり小さくなります. また, SSD に加えて大容量の HDD を使用することも (HDD は主にシミュレーションデータの保存に使用されます) 合理的です.
メモリの追加
この方法では, 物理メモリよりも仮想メモリが大幅に多いモデルでも, すべてのメモリチャネルにバランスよくメモリが追加されている限り, 求解速度が向上します. たとえば, これらのテストに使用した CPU は, 4つのメモリチャネルと 32 GB の RAM を持ち, チャネルごとに1つの8 GB DIMM を備えています. チャネルごとに1つずつ, さらに4つの8 GB DIMM を追加するか (このコンピューターには, メモリチャネルごとに空のセカンドスロットがあるため), 4つの8 GB DIMM をすべて16 GB DIMM に交換することでアップグレードすることが可能です. いずれにせよ, チャネルがすべて埋まっていることが重要です. 例えば, 4つのチャネルのうち1つしか使用されていない場合, 求解速度が遅くなってしまいます.
より高速な DIMM へのアップグレード
CPU によっては, より高いデータ転送速度に対応した DIMM にアップグレードできる場合があります. しかし, DIMM 間のメモリ速度のバランスが悪いと, 一般的にサポートされている最低速度になるため, すべての DIMM が同じ速度であることが重要です.
クロック速度の速い CPU へのアップグレード
クロック速度はソフトウェアのあらゆる側面に影響し, 速ければ速いほど良いです. 実用的な観点からは, 他はそのままでクロックだけを単純にアップグレードすることはできないので, 改善の切り分けができず, ほとんどの場合, 新しいコンピューターを購入することになります. しかし, メモリ使用量が多いモデルになればなるほど, また RAM との間のデータの行き来が多くなればなるほど, CPU 速度よりも RAM メモリとのデータ転送速度が性能のボトルネックになる傾向があります.
コア数の多い CPU へのアップグレード
他の要素を一定に保ったままコア数を増やすアップグレードは難しいため, コア数増加の効果を判断することは容易ではありません. ほとんどの場合, 単一のモデルを解く場合, ジョブごとに8コア以上を使用するメリットはあまりありません. 求解時間が直接線形ソルバーによって支配されている場合は, より多くのコアを使用すると大きなメリットが得られます. 一方, 非常に小さなモデルでは, より多くのコアを使用できる場合でも, 1つのコアで速く解けることがあります. つまり, 小規模なモデルでは, 並列化の計算コスト が大きくなる可能性があります.
これとは別に, COMSOL Multiphysics の バッチスイープ 機能など, 複数のジョブを並行して実行する場合にも複数のコアがあることで有利になります. 現在, 一部の CPU は性能コアと効率コアの両方を提供しており, これによって性能の交換条件が発生します.
より大きなキャッシュを備えた CPU へのアップグレード
キャッシュメモリは大きいに越したことはないですが, キャッシュサイズはコア数に比例するため, キャッシュの高い CPU はコア数が多くなり, 比較的高価になります.
メモリチャネル数の多い CPU を搭載したコンピューターへのアップグレード
シングル CPU のコンピューターでも, 2つ, 4つ, 6つ, あるいは8つのメモリチャネルを搭載したものを購入することは可能です. これらの間の切り替えは, 異なるクラスのプロセッサーの切り替えでもあり, ハードウェアスペックだけで性能を比較することは非常に困難です. 非常に大きなモデルや複数のモデルを並行して解くことが日常的であれば, 4チャネル以上のメモリが必要となります.
デュアル CPU コンピューターへのアップグレード
デュアルソケット対応の CPU は, 1 CPU あたり6または8つのメモリチャネル, 合計12または16チャネルを搭載しており, このようなシステムでは最低でも96 GB の RAM が必要となるため, 主に非常に大きなモデルを解いたり, 多くのモデルを並列で解いたりするためのシステムです.
4 CPU 以上のコンピューターへのアップグレード
これは非常に狭いカテゴリであり, 非常に大量の RAM メモリ (少なくとも768 GB) を必要とするモデルにのみ考慮されるべきものです. このようなシステムを検討している際は弊社のサポートチームにお問い合わせください.
クラスターへのアップグレード
既存のクラスターは数千台あり, そのうちのかなりの割合がすでに COMSOL®の実行に使用されています. 利用可能なクラスターハードウェアのエコシステムは非常に広大で急速に変化しているため, 相対的な性能について説明することは不可能です. また, クラウドコンピューティングサービスプロバイダー を利用すれば, 選択したハードウェアで一時的な計算資源をすばやく起動することができるので, さまざまなハードウェアでの相対的な性能を比較することができます. 非常に大きなモデルを解くという点では, クラスターには ドメイン分割 ソルバーを使えるという利点があります. もちろん, クラスターはクラスタースイープ ノード内で何百, 何千ものケースを並行して解くのにも有効です.
注: これらの要素に加え, プロセッサーの製造年代とアーキテクチャも考慮する必要があります. プロセッサーはほぼ毎年大幅なアップデートが行われており, 年に数回のマイナーなアップデートも行われています. プロセッサーの世代間で上記の指標を比較することは非常に困難ですが, 一般的に新しい世代のプロセッサーは古い世代のプロセッサーよりも優れていると言えるでしょう.
どのコンピューターを購入するか, どのように決めれば良いのでしょうか?
どのようなコンピューターを購入するかを決めるには, まず, 実行したい解析を行うモデル (またはモデル群) を選択します. 次に, シミュレーションの拡大していく必要があるため, 必要なメモリを特定するためのスケーリングスタディを行います. もちろん, 多少の推測や外挿は必要なので, 必要なメモリは多めに見積もるのがよいでしょう.
必要なメモリ容量が見えてきたら, 最新世代のプロセッサーの中から, メモリチャネル数で絞っていきます. 最も自由度が高いのはここなので, ここでぜひとも考えておきたいのがメモリのアップグレードの可能性です. メモリ必要量を過小評価してしまっていた場合, より大容量の RAM を簡単にインストールできるようにしたいものです. 例えば, 先のデータを作成したコンピューターは32 GB の RAM を搭載しており, 1チャネルに1つの8 GB DIMM を搭載した, 4つのメモリチャネルを持つシステムにインストールされています. 1チャネルにつき1スロット空いているので, 8 GBの DIMM をもう4枚購入すれば, 64 GBの RAM にアップグレードすることも簡単です.
次に, プロセッサーの選択ですが, プロセッサーのアーキテクチャが最速のメモリ速度をサポートしているかどうかを確認し, そのアーキテクチャの中で最速のクロック速度を選択します. 一般に, クロック速度とコア数の間にはトレードオフの関係があります. キャッシュサイズはコア数に応じて大きくなる傾向がありますが, メモリチャネルあたり3個以上のコアが搭載されていると, 通常, 性能に対するハードウェアコストが高くなってしまいます.
また, 仮想メモリの大量使用が予想される場合は, SSD ドライブを搭載するなど, いくつかの他の要素も念頭に置いておきましょう. グラフィックスカードに関しては, サポートされているハードウェアのリストは こちら です. より高いメモリと速度を持つグラフィックスカードは, 常により優れたディスプレイ性能を提供します. また, コンピューターは, より高価なワークステーションやより経済的な消費者層など, 特定の市場や異なる価格帯に合わせて作られています. 後者の方がピーク性能が高い場合もありますが, ワークステーションクラスシステムは, 特に非常に大きなモデルを何時間も, あるいは何日も実行する場合, より信頼性が高くなります.
性能を向上させる他の方法とは?
この時点で, モデルを実行するための新しいハードウェアを今すぐ購入したいと思われるかもしれません. しかし, その前に, 自分が構築しているモデルの価値についてお考えください. 価値ある数値モデルとは, キャリアにおいて何千 (あるいはそれ以上!) ものバリエーションを実行することになるものです. これらのモデルの性能を可能な限り効率的にすることで, 数週間から数ヶ月の時間を節約することができます. これは, 使用するハードウェアに関係なく言えることです.
モデルをカテゴリに分類
使用するハードウェアに関係なく, できるだけ早くモデルを実行させる方法を学ぶために, モデルを概念的に3つのカテゴリに分類することができます.
1. 線形定常
これらのモデルには, 材料特性, 荷重, 境界条件などが解に依存しない場合が含まれます. 周波数領域や固有値, 固有振動数モデルもこのカテゴリに分類できます. これらの場合, 計算時間は自由度の数だけに関係するため, 目的の精度を達成しつつ, できるだけ自由度を減らすことを常に目標としなければなりません.
2. 非線形定常
これらのモデルには, ナビエ・ストークス方程式系など支配方程式に非線形項がある場合や, 材料特性, 荷重, 境界条件などが解の関数となる場合などが含まれます. このような場合, 線形化された問題を繰り返し解くことで解を求めます. このとき, 必要な計算時間は, 線形化された反復のコストと非線形問題の収束率の組み合わせです. 計算コストの削減には, 目的の精度を達成しつつ自由度をできるだけ低く保つだけでなく, 非線形収束率を向上させることが必要です. つまり, 解に到達するまでにかかるステップ数を減らすことです. 自由度の低減が求解時間とメモリの両方に影響するのに対し, 収束率はほぼ求解時間のみに影響します.
3. 過渡
これらのモデルは, 離散的な数の時間ステップで定常近似のシーケンスを解くことによって, 時間の経過とともに解を計算し, 非線形項を含む場合もあれば, 含まない場合もあります. また, 時間的に変化する場を求解するのに十分なメッシュを持ちながら, 離散的な時間ステップの数を減らし, 時間ステップごとに必要な線形化ステップの数を減らすことも重要な課題となってきます.
モデリングに役立つテクニック
問題はそれぞれ異なりますが, すべての解析者が覚えておくべき, 非常に一般的なテクニックがいくつかあります.
- インポートされた CAD ファイルを扱う場合, よりシンプルなジオメトリを得るための 細部除去 および 仮想操作 機能を使った, CAD データの近似, および対称性 を使った CAD モデルのサイズ縮小.
- 比較的薄い, あるいは小さいジオメトリがある場合, 構造モデリングの シェルとビーム の例のように, 簡略化したジオメトリと, 場合によっては異なるフィジックスインターフェースの使用. あるいは, 薄いドメインのジオメトリをモデル化する代わりに, 特殊な境界条件を使用すること.
- 合理的な範囲で スウェプトメッシュ と アセンブリメッシュ を使い分け, 手動でメッシュを構築する 方法を熟知すること.
- 非線形定常問題については, 収束を達成し, 加速するための様々な方法 を理解すること.
- 過渡問題では, 収束性を高める ための様々な方法を理解すること.
もちろん, これらは大まかな流れに過ぎません. 狭い範囲にしか適用できないけれど, モデルをより効率的にしてくれる特殊なモデリング手法は無数にあります. これらのテクニックを習得し, いつ, どのように適用するかが, 経験豊富な数値モデラーの技量になります.
最後に
このブログでは, 一見単純な質問から始まり, それに答えるうちに様々なトピックに触れることができました. このブログの締めくくりとして, 少し物議をかもすかもしれませんが, 自説をお話ししましょう. 私の意見では, より大きなモデルをより高速なコンピューターで解こうとすることは, 最後の手段としての計算方法です. ハードウェアに関係なく, モデルをより小さく, より高速にする方法を研究することに時間を費やした方がはるかに良いと考えます. いずれは, 本格的なハードウェアに投資しなければならない時が来ますが, その時には, なぜアップグレードする必要があるのかを正確に知りたいと思うはずです. このブログを読んでいただいたことで, このプロセスへのアプローチ方法を理解するための枠組みができることを期待します.
Intel および Xeon は, Intel Corporation またはその子会社の商標です.
Microsoft および Windows は, 米国およびその他の国における Microsoft Corporation の登録商標です.
コメント (0)