COMSOL Multiphysics® における GPU アクセラレーション
COMSOL Multiphysics® の最新バージョンでは, NVIDIA® GPU を用いたシミュレーション高速化のための新機能が導入されています. これらの機能強化により, GPU ハードウェアの恩恵を受けられるモデルの範囲が広がりました. あらゆるシングルフィジックスまたはマルチフィジックスアプリケーションに適用可能な直接疎行列ソルバーに加え, 圧力音響 (陽的時間発展) シミュレーションとディープニューラルネットワーク (DNN) 代理モデルトレーニングのサポートも含まれています. バージョン 6.4 では, 直接法ソルバーの GPU サポートが標準ソルバーフレームワークに完全に統合されているため, ユーザーは基盤となる物理設定を変更することなく, 既存モデルで GPU アクセラレーションを活用できます.
直接疎行列ソルバーの GPU アクセラレーション
有限要素シミュレーションにおいて, 最も時間を要する段階の一つは, 大規模な疎線形方程式の繰り返し計算です. このようなシステムは, 陰的時間ステップ, 非線形反復, 固有振動数解析, パラメータースイープなどから生じます. こうした種類の解析に対応するため, COMSOL Multiphysics® バージョン 6.4 には NVIDIA CUDA® 直接疎行列ソルバー (cuDSS) が搭載されました. このソルバーは, 最新の GPU ハードウェアが提供する高いメモリ帯域幅と大規模な並列処理を活用し, 1台のコンピューター上の単一もしくは複数の GPU を使用して行列分解を実行します.
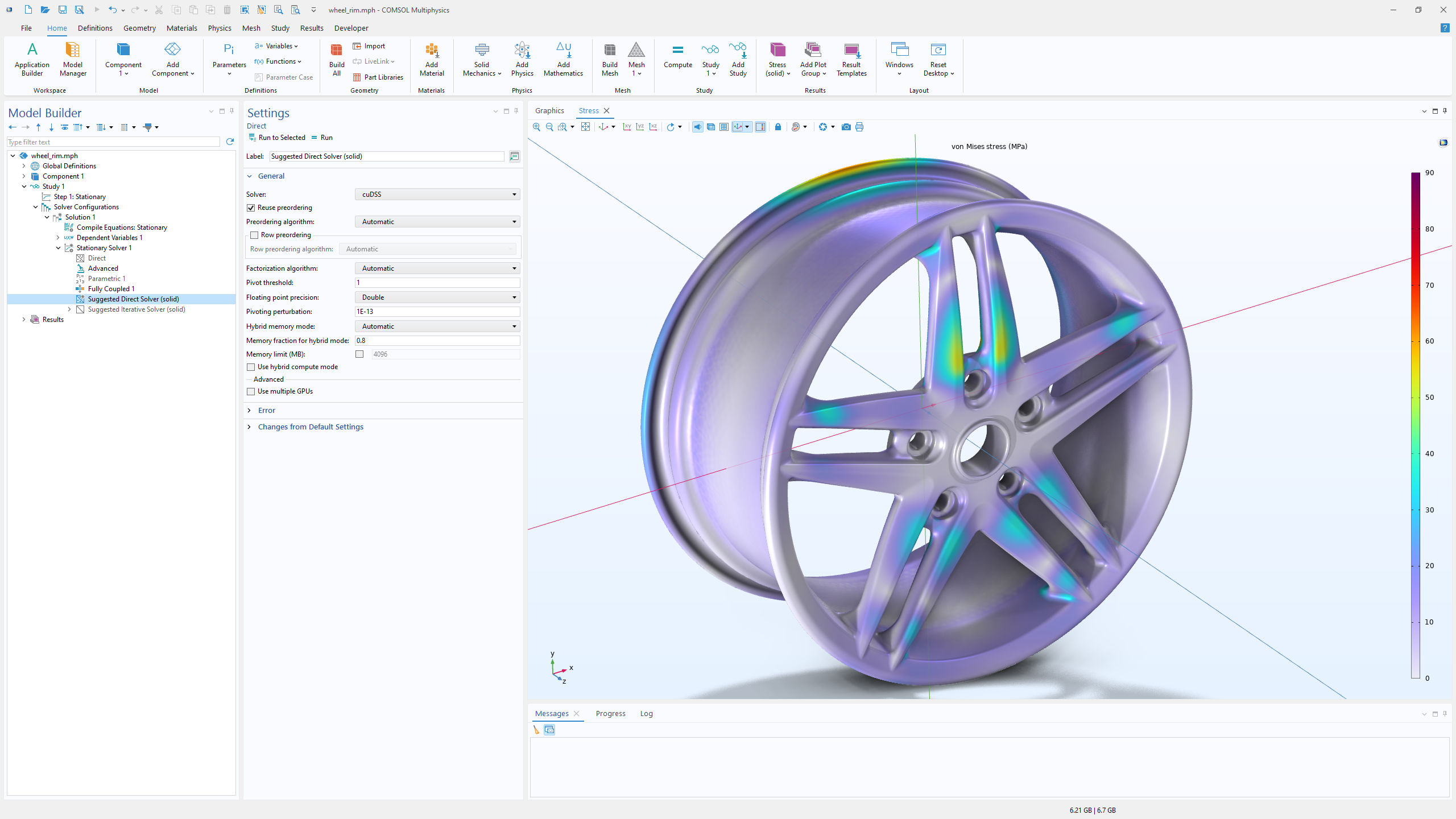
性能の向上はアプリケーションによって異なりますが, 数百万の自由度 (DOF) を持つモデルでは, 経過実時間の大幅な短縮が確認されています. 例えば, 穿孔板を通る音響伝達のマルチフィジックス解析を含む熱粘性音響ベンチマークシミュレーションでは, 複数の NVIDIA® H100 GPU での解法により, デュアルプロセッサー CPU システムと比較して実行時間が大幅に短縮されました. 標準的な構造力学モデルにおいても, 直接ソルバーの段階を RTX 5000 Ada などのワークステーションクラスの GPU にオフロードすることで, 明らかな改善が確認されています.
cuDSS の実装は倍精度および単精度演算の両方をサポートします. 単精度はメモリ使用量を半分に削減するため, アプリケーションがメモリ制約を受けるあらゆるカード (低コスト GPU を含む) において性能向上をもたらします. 特定のモデルが単精度に適しているかどうかは, メッシュ品質, 材料パラメーター, 基礎となるフィジックスに影響される数値的な条件に依存します. ユーザーはソルバー設定内で直接精度の各モードをテストし, 安定した結果と望ましいパフォーマンスの両方を提供するモードを選択できます.
GPU アクセラレーションによる圧力音響 (陽的時間発展)
NVIDIA® GPU サポートは, 圧力音響 (陽的時間発展) シミュレーションにも対応しています. こうした種類のシミュレーションを実行する場合, 各時間ステップで大規模な線形連立方程式を解く必要性を回避できます. 代わりに, 反復的なベクトル演算と局所的な要素更新に依存する陽的時間解法を使用することで, これらの演算は高度に並列化されており, GPU ハードウェアに効率的にマッピングできます.
この機能は, 広帯域音響シミュレーションや大規模 3D ドメインにおいて有効です. これらのドメインでは, 細かい空間解像度により多数の時間ステップが必要となります. 例えば, オフィス空間やコンサートホールなどの室内音響モデルでは, 波動伝播を正確に解析するために数万もの時間ステップが必要になる場合があります. これらの演算を GPU にオフロードすることで, シミュレーション全体の所要時間を大幅に短縮できます.
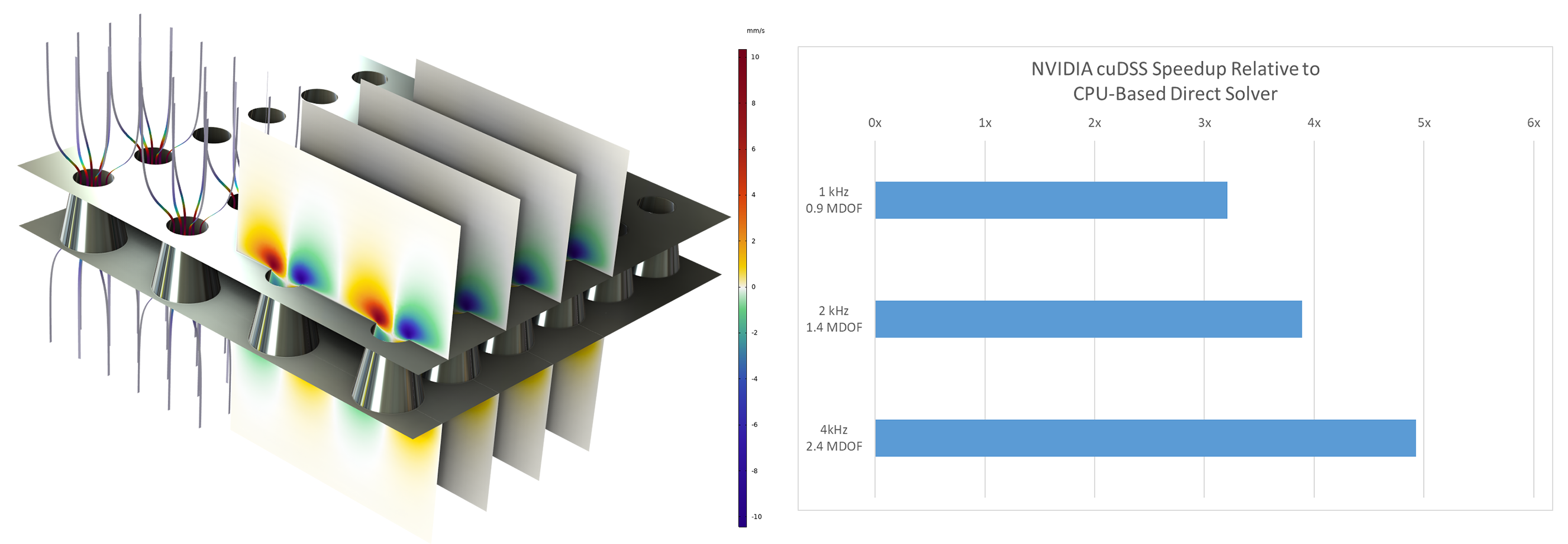
GPU アクセラレーションによる陽的音響解析の定式化は, 単一 GPU システム (バージョン 6.3 で導入) と複数 GPU システム (バージョン 6.4 で導入) の両方をサポートし, 単一のコンピューターおよび複数クラスターノードの両方で使用できます. これにより, 数億の自由度を持つドメインをシミュレーションが可能となります. 例えば, 室内楽ホールの波動ベースモデルでは, 約3億の自由度 (DOF) を含むシミュレーションが, データセンターグレードの NVIDIA® H100 GPU 1台で数時間以内に完了しました. これは複数の CPU ノードでの数時間と比較して大幅な短縮となっています. 自動車音響の事例やその他の大規模な過渡解析においても, 同様の実行時間の短縮が確認されています.
注: 圧力音響 (陽的時間発展) インターフェースは, 単一の GPU を使用する場合はすべてのライセンスタイプでサポートされますが, 複数の GPU を使用する場合はフローティングネットワークライセンスが必要です.
3億の自由度 (DOF) を有する室内楽ホールモデルにおける初期パルス (中心周波数 500 Hz) の伝播解析. データセンターグレードの NVIDIA® H100 GPU 上で解析.
代理モデルトレーニングの GPU サポート
バージョン 6.3 以降, COMSOL Multiphysics® は, 高フィデリティの数値シミュレーションを近似するディープニューラルネットワーク (DNN) 代理モデルを生成するためのツールも提供しています. これらのネットワークの学習には, 大規模なデータセットの反復評価と多数の最適化サイクルが必要であり, GPU アクセラレーションに適しています. 学習プロセスを NVIDIA® GPU 上で実行することで, ネットワークアーキテクチャの探索やハイパーパラメーターの調整にかかる時間を短縮できます.
複雑なマルチフィジックス挙動の捕捉や空間モデル再構築には より大規模なネットワークが必要となることがあります. このような場合には, GPU の増大したメモリ帯域幅と並列計算能力の恩恵を受けることができます. DNN 学習に対する GPU サポートは, 代理モデル インターフェース内で直接有効化することができ, アドオン製品なしで機能します.
関連資料
COMSOL Multiphysics® における GPU アクセラレーションの詳細については, 以下を参照してください:
- COMSOL Multiphysics® 6.4 リリースハイライト: スタディとソルバーのアップデート
- COMSOL Multiphysics® 6.4 リリースハイライト: 音響モジュールアップデート
- システム要件: COMSOL Multiphysics® バージョン 6.4
- COMSOL Multiphysics® における GPU アクセラレーション計算の設定
NVIDIA, CUDA, および RTX は, 米国およびその他の国における NVIDIA Corporation の商標および/または登録商標です. Intel および Xeon は, 米国およびその他の国における Intel Corporation の商標です.